FIDDLER: CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models
ICLR 2024
Keisuke Kamahori, Yile Gu, Kan Zhu, Baris Kasikci
University of Washington
OpenSource : https://github.com/efeslab/fiddler
Background
Existing systems use parameter offloading (offload model weights to CPU memory) when there are no enough GPU memory to run MOE models, but it may suffer from the significant overhead of frequently moving data between CPU and GPU.
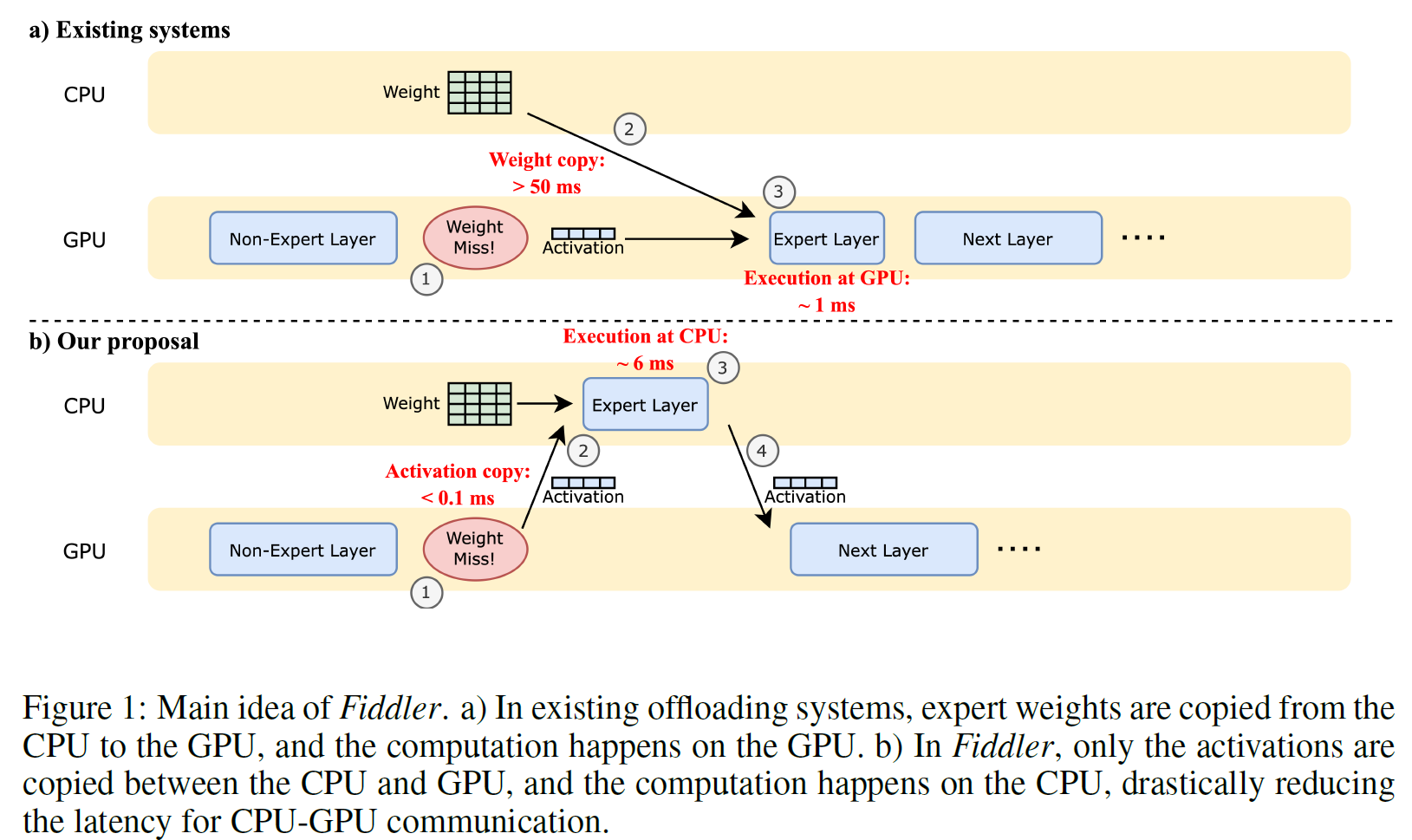
Solution
In terms of latency, it is better to execute expert layers on the CPUs than to load the expert weights from CPU memory to GPU memory, especially when the batch size is small
Evaluation
Fiddler can run the uncompressed Mixtral-8x7B model, which has more than 90GB of parameters, to generate over 3 tokens per second on a single GPU with 24GB memory. Compared to existing offloading methods, Fiddler improves the single-batch inference latency by 8.2 times on Quadro RTX 6000 and 10.1 times on L4 GPU on average across different input/output lengths.