OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models
arxiv 2024
Fuzhao Xue (1), National University of Singapore Yang You1 (CA), National University of Singapore
Background
To help the open-source community have a better understanding of MoE based LLMs, they train and release Open-MoE, and do an in-depth analysis of the routing mechanisms within OpenMoE models.
Result
1. Context-Independent Specialization
MoE tends to simply cluster tokens based on similar token-level semantics, implying that, regardless of context (high-level semantics), a certain token is more likely to be routed to a certain expert;
Possible Reason: They infer that the reason is that, when the token is usually assigned to one specific expert, the loss would increase a lot if the token is sent to another unseen expert, which pushes the model to assign the token back to the original expert.
As shown is Figure, All these tokens show a very strong specialization on only a few experts.
As shown is Figure, experts may cluster similar tokens (but still no matter what the context is).
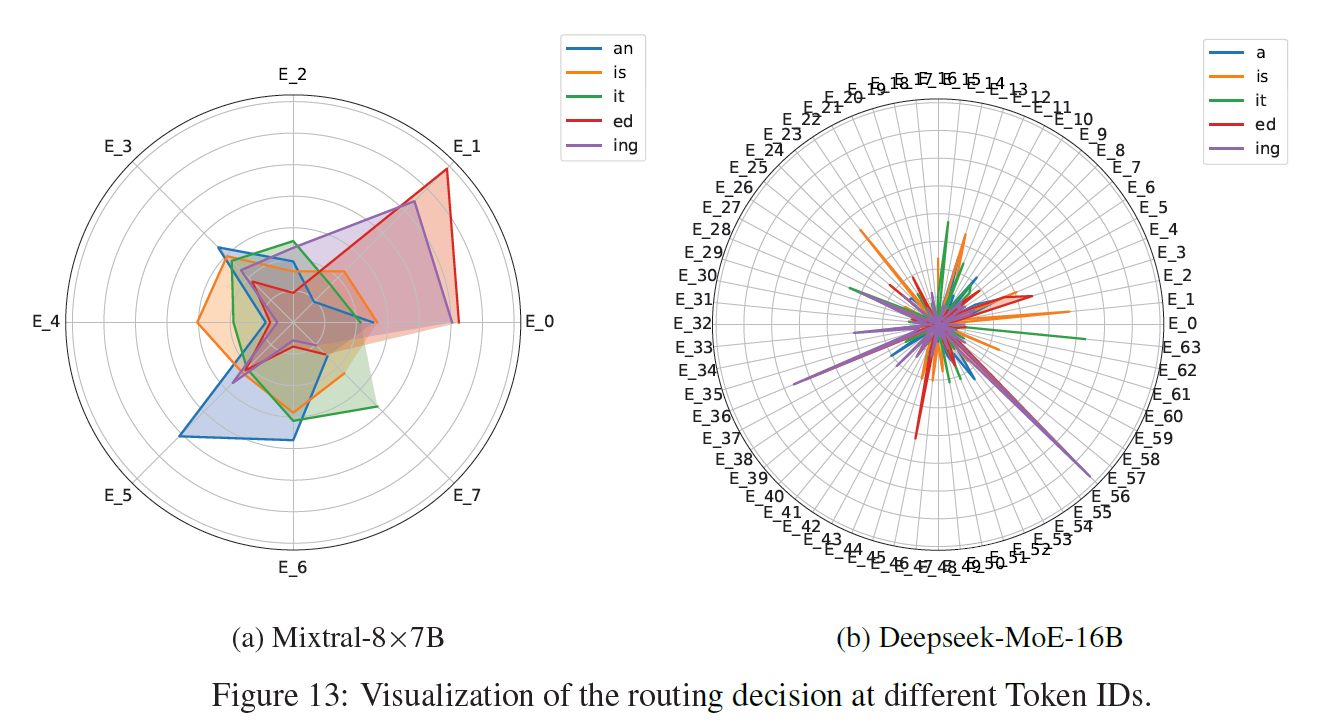
2. Early Routing Learning
Token ID routing
specialization is established early in pre-training and remains largely fixed, resulting in tokens being consistently processed by the same experts throughout the training; (在前期的batch即确立这种关系,微调也不会改变)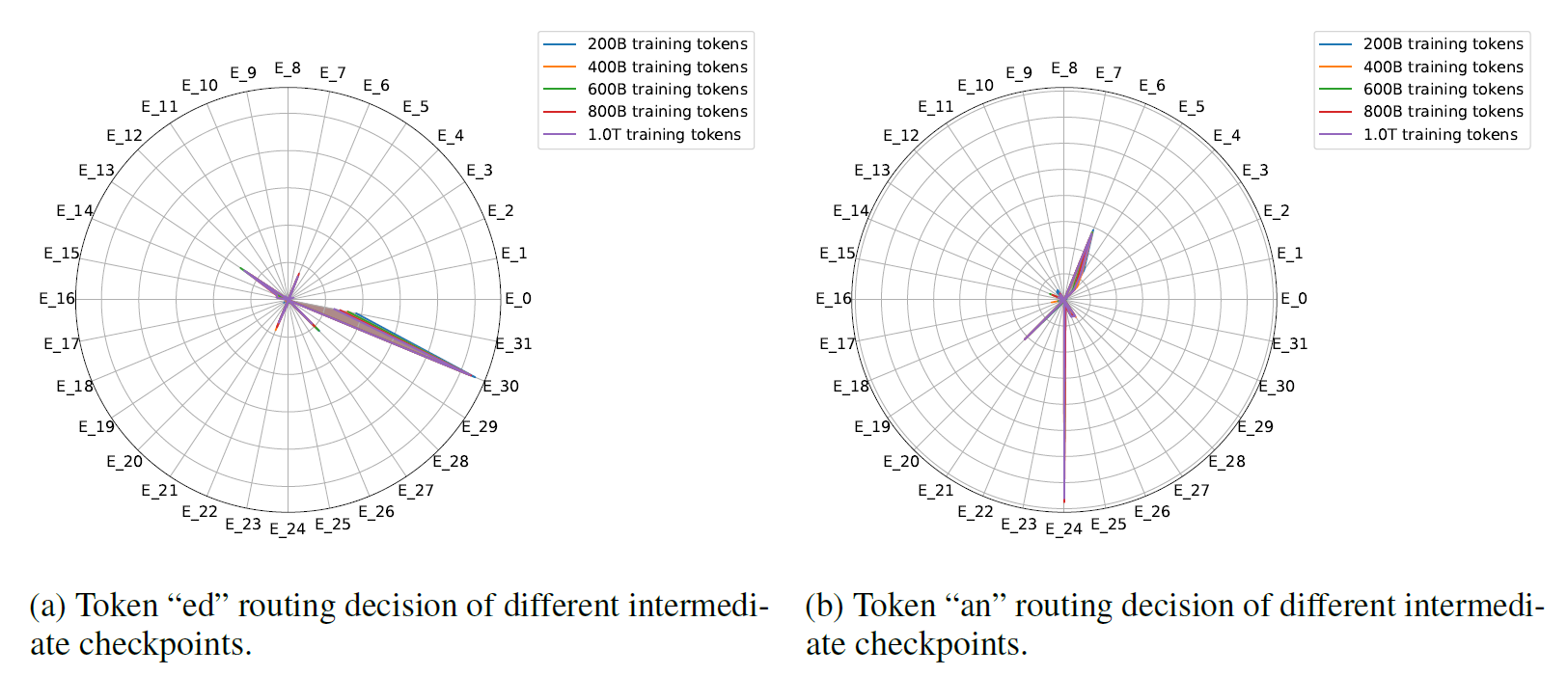 As shown is Figure, the expert preferences are almost totally overlapped for different checkpoints, which means that the model has started to fix its routing at the very early stage of training.
As shown is Figure, the expert preferences are almost totally overlapped for different checkpoints, which means that the model has started to fix its routing at the very early stage of training.
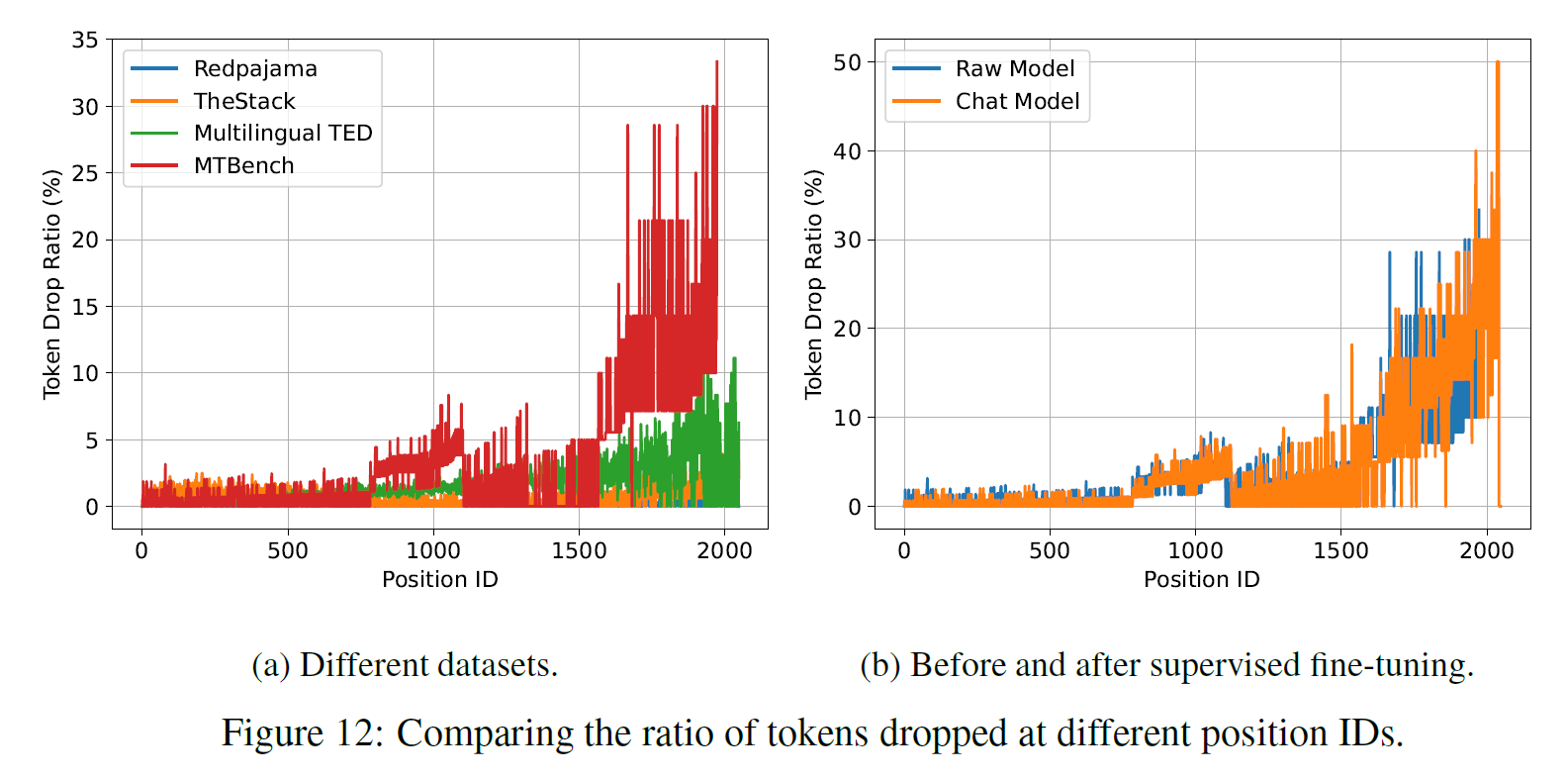
3. Drop-towards the-End.
Since each expert has a fixed max capacity, tokens appearing later in the sequence face a higher risk, which can result in performance degradation. (有些模型训练时及时超过capabilities也不会dropout,则不会影响准确性, eg: Mixtral and Deepseek-MoE have no token drop mechanism.)