A. Context:
When dealing with dynamic workload,
virtual machines => need to size the cluster to handle the largest stage => resources will idle during other stages.
serverless platform => resources can be immediately released after use => improve resource utilization
- serverless functions have fine-grained elasticity, match workload requirments with continuous scaling.
a. Current Problem:
Due to resource limits and performance variations, its challenge to efficienly execute complex workloads (data analytics workloads) that invove communication across functions.
main reason: slow data shuffle bewteen asynchronous serverless function invocation.
direct transfer sometimes not feasible [Tasks are short-lived]:
- (1) cloud providers do not provide any guarantees on when functions are executed and hence the sender and receiver workers might not be executing at the same time.
- (2) even if the sender and receiver overlap, given the execution time limit, there might not be enough time to transfer all the necessary data.
intermediate data between stages need to be persisted on shared storage.
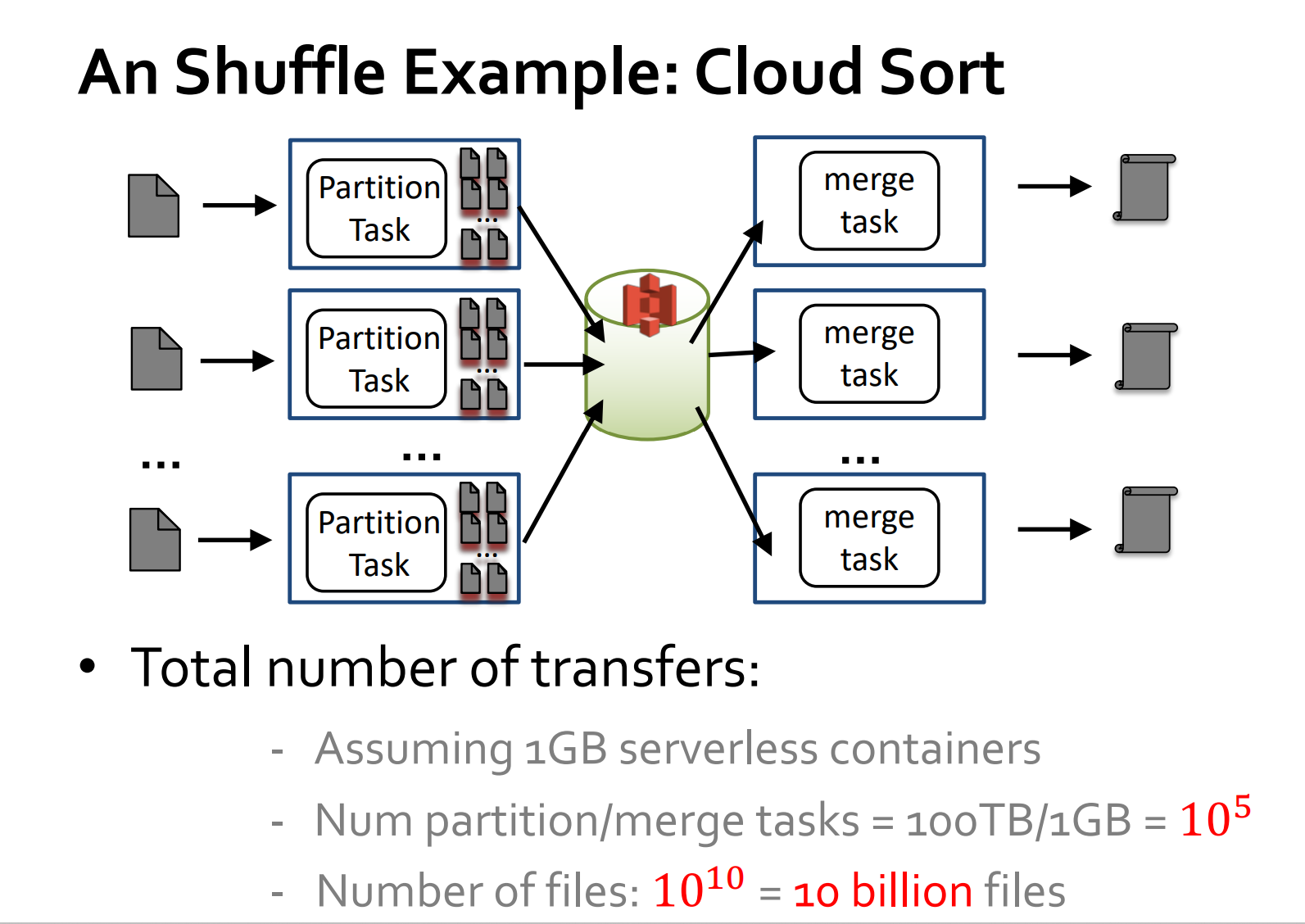
note1:functions have resource limitations (memoey here) which limits the amount of data a function can process in one task. So we need lots of Map Tasks and Merge Tasks. So that the inputs to the tasks can be less than the memory footprint of a function.EG. Map tasks=M, Merge tasks=N,=> partition numbers in each Map tasks=N, number of files generated after map=M*N
note2:throughput limits of object stores like Amazon S3 can lead to significant slow downs. storage main characteristic: read and write throughput (in terms of request/sec, referred as IOPS) and bandwidth (in terms of bytes/sec)can be a bottleneck (note: each request respond to single file)
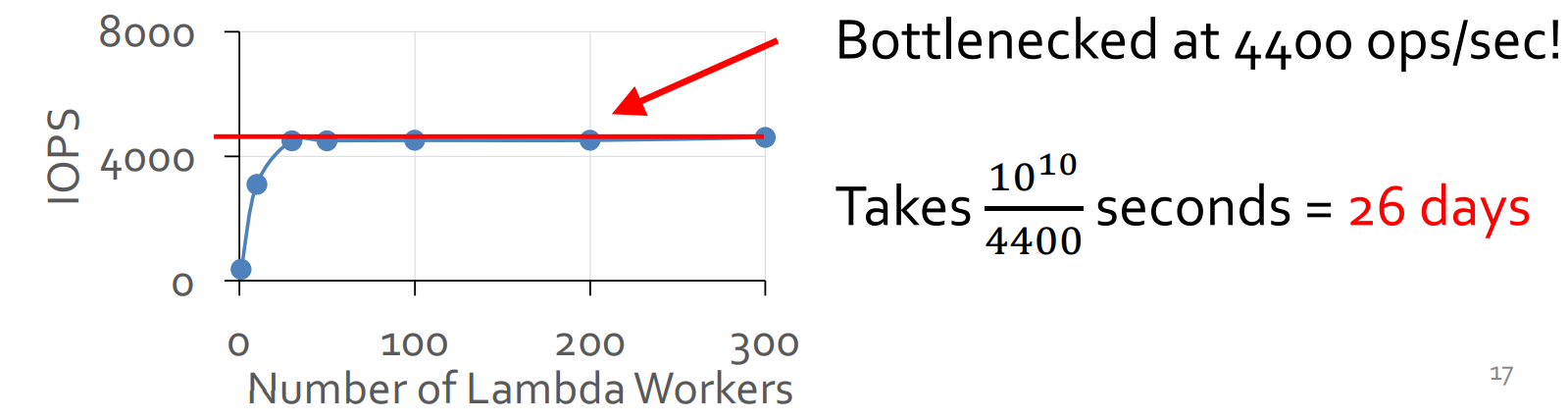
Also, these values (IOPS / bandwidth) are not stable as we change the degree of parallelism and worker memory size.
B. Contribution
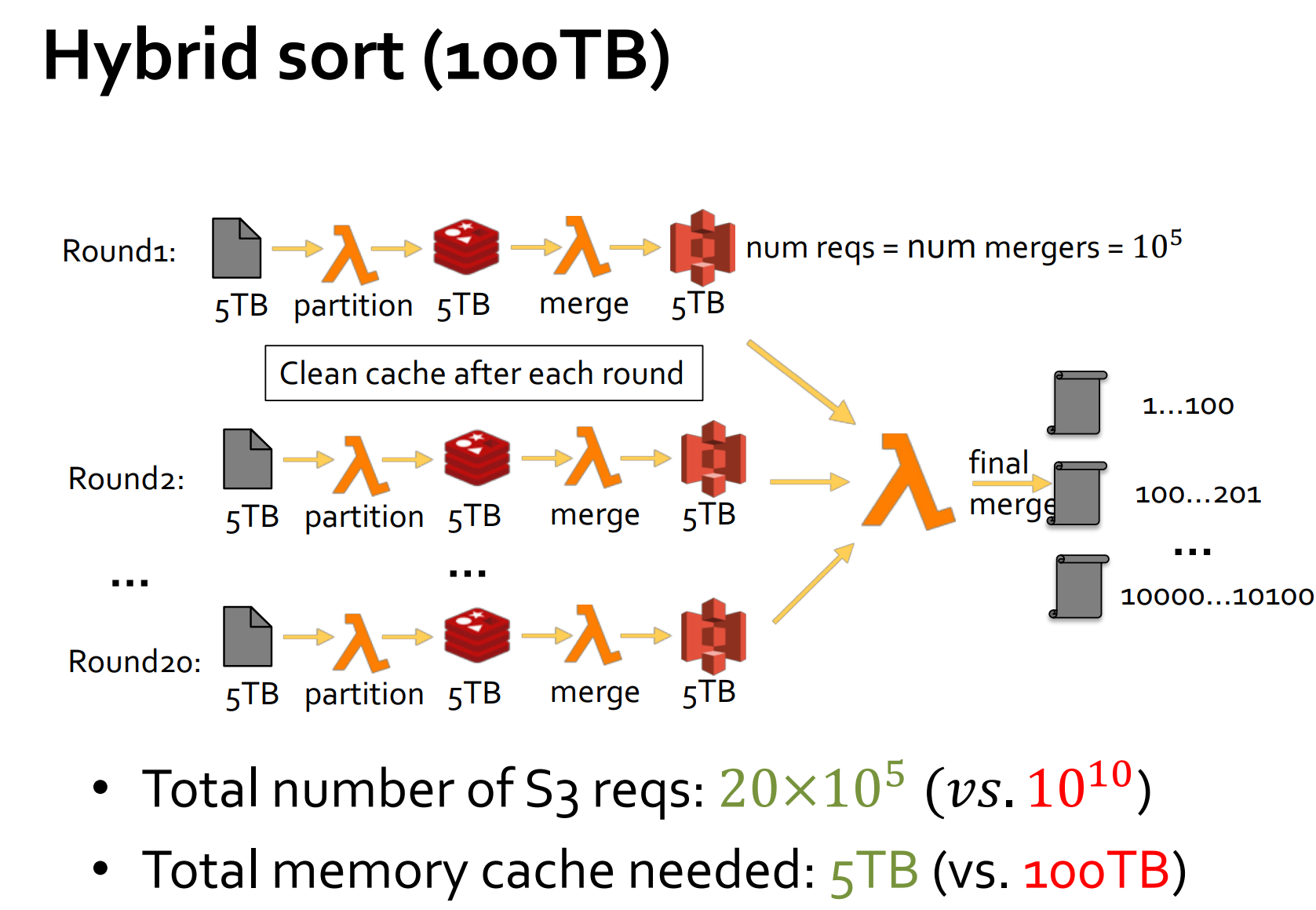
Idea: Hybrid slow and fast cloud storage to achieve costefficient shuffle performance
- fast storage: expensive, high IOPS, low capacity
- slow storage: cheap, high capacity, how IOPS
To do that, we introduce a multi-round shuffle that uses fast storage for intermediate data within a round, and uses slow storage to merge intermediate data across rounds. In each round we range-partition the data into a number of buckets in fast storage and then combine the partitioned ranges using the slow storage. We reuse the same range partitioner across rounds.

In this way, we can use a merge stage at the end to combine results across all rounds, as illustrated in Figure 3. For example, a 100 TB sort can be broken down to 100 rounds of 1TB sort, or 10 rounds of 10TB sort